\newpage
Introduction au Lab 5 :
Ce TP marque la transition entre la gestion manuelle de l’infrastructure (réalisée au Lab 4) et l’automatisation complète via des pipelines CI/CD. L’objectif est de mettre en place un environnement où chaque modification de code est testée, validée et déployée sans intervention manuelle, en utilisant GitHub Actions comme orchestrateur et AWS comme fournisseur Cloud.
Intégration Continue (CI)
Principes Théoriques de la CI
L’Intégration Continue (CI) consiste à fusionner les modifications de code dans la branche principale (main) le plus fréquemment possible. Cette approche repose sur plusieurs piliers que nous avons appliqués durant ce TP :
-
Trunk-based development : Utilisation de branches à courte durée de vie et de Pull Requests pour minimiser les conflits de fusion.
-
**Self-testing build : **Chaque commit déclenche automatiquement une suite de tests pour garantir que le code reste fonctionnel.
-
**Gestion des changements majeurs : ** Introduction de concepts comme les Feature Toggles (pour activer/désactiver des fonctionnalités) et le Branch by Abstraction (pour les refontes lourdes).
Automatisation des Tests Applicatifs (Node.js)
La première étape concrète a consisté à configurer un workflow GitHub Actions pour tester notre application Node.js (sample-app) à chaque modification.
Configuration du Workflow
Nous avons créé le fichier .github/workflows/app-tests.yml. Ce script définit un environnement Ubuntu virtuel qui installe les dépendances et exécute la suite de tests Jest.
Extrait du workflow :
name: Sample App Tests
on: push
jobs:
sample_app_tests:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Install dependencies
working-directory: td5/scripts/sample-app
run: npm install
- name: Run tests
working-directory: td5/scripts/sample-app
run: npm testMise en pratique et Validation du Workflow
Pour valider l’efficacité de notre CI, nous avons suivi une approche de “Test-Driven Development” inversée :
-
Nous avons modifié le texte de réponse dans app.js (“DevOps Labs!”) sans mettre à jour le test associé.
-
La Pull Request a affiché un échec du workflow. Cela prouve que la pipeline protège la branche main contre l’introduction de régressions.
-
Après avoir mis à jour app.test.js pour correspondre à la nouvelle réponse, le workflow est passé au vert.
 Capture d’écran du workflow GitHub Actions réussi.
Capture d’écran du workflow GitHub Actions réussi.
Authentification et Sécurisation des Déploiements (OIDC)
Stratégie d’authentification : Machine User vs OIDC
Pour automatiser le déploiement de ressources AWS via OpenTofu, une authentification robuste est nécessaire. Nous avons étudié deux approches :
Machine User Credentials : Utilisation d’un compte utilisateur dédié avec des clés d’accès statiques. Cette méthode présente des risques de sécurité majeurs (clés à longue durée de vie, gestion manuelle).
Automatically-Provisioned Credentials (OIDC) : Utilisation de jetons dynamiques à courte durée de vie. C’est la méthode recommandée que nous avons implémentée pour ce TP.
Configuration du fournisseur OIDC avec AWS
L’objectif est de permettre à GitHub Actions de s’authentifier auprès d’AWS de manière sécurisée sans stocker de secrets permanents. Pour cela, nous avons créé un module racine dans td5/scripts/tofu/live/ci-cd-permissions.
Nous avons utilisé le module github-aws-oidc pour déclarer GitHub comme fournisseur de confiance.
module "oidc_provider" {
source = "../../modules/github-aws-oidc"
provider_url = "https://token.actions.githubusercontent.com"
}Création des Rôles IAM pour le CI/CD
Une fois la confiance établie, nous avons configuré les rôles nécessaires pour les différentes étapes de notre pipeline à l’aide du module gh-actions-iam-roles. Ces rôles permettent d’appliquer le principe du moindre privilège.
Nous avons activé trois types de rôles spécifiques :
- Testing Role : Pour les tests d’infrastructure.
- Plan Role : Pour l’inspection des changements (lecture seule).
- Apply Role : Pour l’application réelle des modifications (écriture).
module "iam_roles" {
source = "../../modules/gh-actions-iam-roles"
name = "lambda-sample-lina"
oidc_provider_arn = module.oidc_provider.oidc_provider_arn
enable_iam_role_for_testing = true
enable_iam_role_for_plan = true
enable_iam_role_for_apply = true
github_repo = "Lina-Ouchaou-Amroussi/devops-base"
tofu_state_bucket = "tofu-state-lina-amroussi-unique-2026"
}Déploiement et Récupération des ARNs
Après avoir initialisé le module avec tofu init, nous avons exécuté tofu apply. Cette étape a généré les Amazon Resource Names (ARN) indispensables pour la configuration des secrets GitHub.
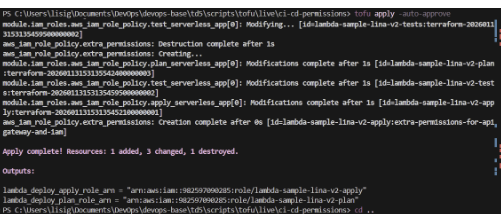 Capture d’écran de notre terminal après le
Capture d’écran de notre terminal après le tofu apply.
On voit l’exécution de tofu apply dans le dossier ci-cd-permissions et on voit clairement les ARNs générés (lambda_deploy_apply_role_arn et lambda_deploy_plan_role_arn).
Ces ARNs (lambda_test_role_arn, etc.) servent de pont entre GitHub Actions et AWS. En les utilisant, GitHub peut demander à AWS de lui prêter les pouvoirs associés à ces rôles pour une durée limitée, garantissant ainsi une sécurité maximale de notre chaîne de livraison.
Automatisation des Tests d’Infrastructure (CI)
L’objectif de cette étape est de valider que les modifications du code OpenTofu ne brisent pas l’infrastructure avant qu’elles ne soient fusionnées. Cette approche “Fail Fast” permet de détecter les erreurs de configuration (syntaxe, permissions, limites AWS) dès l’ouverture d’une Pull Request.
Dynamisation et Modularité via les Variables
Pour permettre à la pipeline de créer des ressources uniques par exécution, nous avons rendu le module flexible en modifiant le fichier td5/scripts/tofu/live/lambda-sample/variables.tf.
Sans cette dynamisation, deux pipelines s’exécutant en même temps provoqueraient une erreur car elles tenteraient de créer la même fonction Lambda avec le même nom.
variable "name" {
description = "The base name for the function and all other resources"
type = string
default = "lambda-sample-lina-v2"
}Dans le fichier main.tf, nous avons substitué les noms statiques par cette variable var.name pour les modules function, gateway et lambda_permission. Cela garantit une isolation parfaite entre les environnements de test.
Workflow de Test d’Infrastructure (infra-tests.yml)
Ce workflow constitue notre premier rempart de sécurité. Il utilise une authentification temporaire via OIDC pour exécuter la suite de tests intégrée d’OpenTofu.
Analyse du script de pipeline :
steps:
- uses: actions/checkout@v2
- uses: aws-actions/configure-aws-credentials@v3
with:
role-to-assume: ${{ secrets.TEST_ROLE_ARN }}
aws-region: eu-north-1
- uses: opentofu/setup-opentofu@v1
- name: Tofu Test
env:
TF_VAR_name: lambda-sample-${{ github.run_id }}
run: |
tofu init -backend=false -input=false
tofu test -verboseLes points importants ici :
-
Nous utilisons l’ID unique de l’exécution GitHub (${{ github.run_id }}) pour nommer la Lambda de test. Ainsi, chaque test dispose de son propre espace de nommage sur AWS.
-
Initialisation Sans Backend (-backend=false) : Comme les tests d’infrastructure sont éphémères et destinés à être détruits immédiatement, nous désactivons le stockage de l’état (State) dans S3 pour gagner en rapidité et éviter de polluer notre backend de production.
-
Mode Verbeux (-verbose) : permet de tracer précisément chaque étape du fichier deploy.tftest.hcl, facilitant le débogage en cas d’échec des assertions HTTP.
Continuous Delivery (CD)
Stratégie de Déploiement et Approche Méthodologique
Le passage à la “livraison” continue repose sur le choix d’une stratégie de déploiement capable de garantir la stabilité de l’application tout en automatisant les mises à jour. Pour notre architecture Lambda, nous avons privilégié une stratégie de déploiement progressif sans remplacement. Cette approche est particulièrement adaptée aux architectures qui n’utlisent pas de serveur car elle permet de traiter les requêtes entrantes de manière ininterrompue pendant que la nouvelle version du code est déployée par AWS. En complément, nous avons instauré un mécanisme qui va séparer la phase de planification de celle de l’exécution. Cette répartition permet d’assurer une validation de notre part du plan d’infrastructure avant toute modification réelle, réduisant ainsi les risques d’erreurs .
Migration vers le Backend Distant et Persistance de l’État
Nous avons configuré un bucket S3 pour assurer l’efficacité du fichier .tfstate, couplé à une table DynamoDB pour la gestion du verrouillage. Le module state-bucket a été instancié pour créer ces ressources avec des paramètres de sécurité stricts, notamment le chiffrement au repos.
# Configuration du module de stockage de l'état
module "state" {
source = "../../modules/state-bucket"
name = "tofu-state-lina-amroussi-unique-2026"
}
# Configuration du backend dans le module applicatif
terraform {
backend "s3" {
bucket = "tofu-state-lina-amroussi-unique-2026"
key = "td5/scripts/tofu/live/lambda-sample/terraform.tfstate"
region = "eu-north-1"
encrypt = true
dynamodb_table = "tofu-state-lina-amroussi-unique-2026"
}
}Architecture des Rôles IAM et Elévation des Privilèges
La gestion des identités via OIDC constitue l’aspect le plus complexe du déploiement. Nous avons utilisé le module gh-actions-iam-roles pour définir les rôles de Plan et d’Apply. Cependant, nous avons dû étendre les permissions par défaut pour permettre à la pipeline de lire et modifier les ressources IAM liées à la Lambda. Pour le rôle de Plan, nous avons ajouté une fonction de lecture afin d’autoriser l’inspection des rôles existants, évitant ainsi les erreurs AccessDenied lors de la phase de comparaison.
# Extension des permissions pour le rôle de Planification
resource "aws_iam_role_policy" "plan_extra_permissions" {
name = "plan-permissions-read-iam"
role = "lambda-sample-lina-v2-plan"
policy = jsonencode({
Version = "2012-10-17"
Statement = [{
Effect = "Allow"
Action = ["iam:Get*", "iam:List*", "apigateway:Get*", "lambda:Get*", "s3:Get*"]
Resource = "*"
}]
})
}Pour le rôle d’Apply, une portée plus large a été nécessaire car le déploiement d’une Lambda implique la gestion complète de son rôle d’exécution. Nous l’avons donc configuré en autorisant les actions sur IAM, l’API Gateway et les fonctions Lambda, tout en sécurisant l’accès par une relation de confiance restreinte à notre dépôt GitHub.
# Extension des permissions pour le rôle d'Application (Apply)
resource "aws_iam_role_policy" "extra_permissions" {
name = "extra-permissions-for-apigateway-and-iam"
role = "lambda-sample-lina-v2-apply"
policy = jsonencode({
Version = "2012-10-17"
Statement = [{
Effect = "Allow"
Action = ["iam:*", "apigateway:*", "lambda:*", "s3:*", "dynamodb:*"]
Resource = "*"
}]
})
}Une fois cette configuration finalisée, nous avons testé la réactivité de la pipeline via un commit direct sur la branche principale. Le workflow tofu-apply.yml s’est exécuté avec succès, utilisant le rôle IAM privilégié pour appliquer les changements via la commande tofu apply -auto-approve. Cette étape a permis de valider que la pipeline possède bien les droits nécessaires pour modifier l’infrastructure de manière atomique et sans intervention humaine.
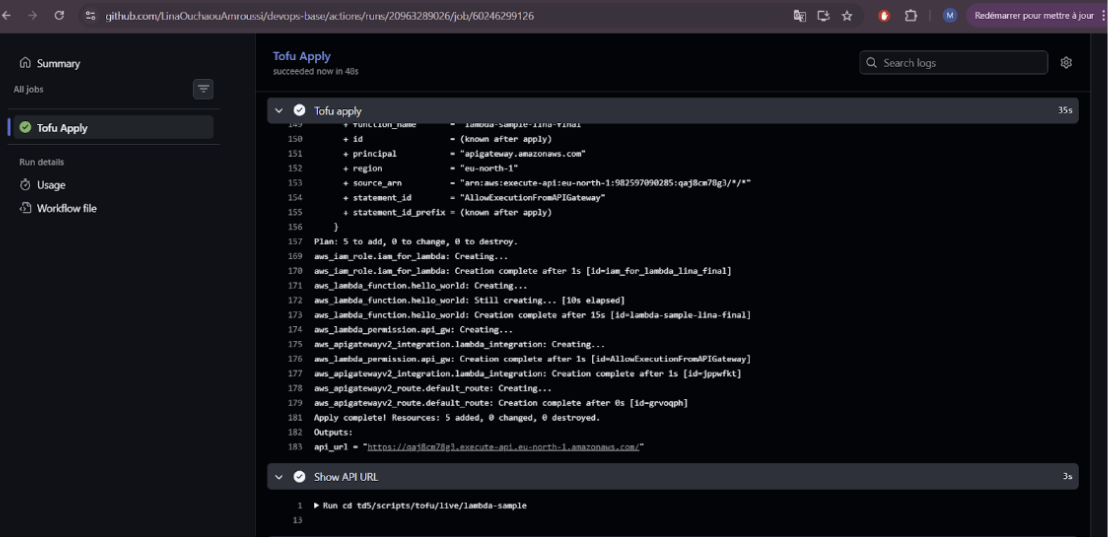 Validation du déploiement initial - Job Tofu Apply
Validation du déploiement initial - Job Tofu Apply
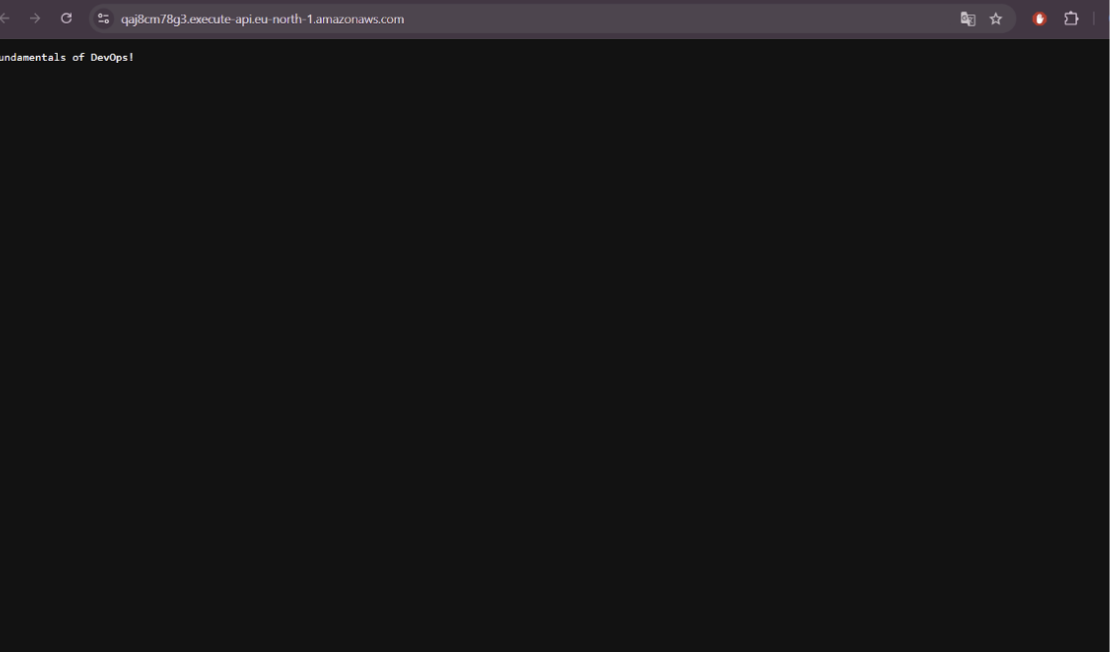 Validation du déploiement initial - Confirmation sur navigateur
Validation du déploiement initial - Confirmation sur navigateur
On observe le succès du job Tofu Apply et la confirmation visuelle immédiate sur le navigateur, prouvant que les permissions IAM et le backend sont correctement configurés.
Automatisation des Workflows et Validation par Pull Request
La mise en œuvre opérationnelle de notre CI/CD repose sur l’utilisation systématique des Pull Requests comme point de contrôle. Dès que nous avons poussé la modification du message applicatif sur une branche séparée, le workflow tofu-plan.yml s’est déclenché. Ce mécanisme est essentiel : il assume le rôle IAM de lecture seule pour générer un aperçu technique des modifications proposées sans impacter l’infrastructure réelle. L’apport majeur de cette étape réside dans l’automatisation du feedback ; OpenTofu va nous donner les sorties en commentaire de la Pull Request. Cela nous permet donc d’inspecter visuellement les changements avant de valider la fusion vers la branche principale.
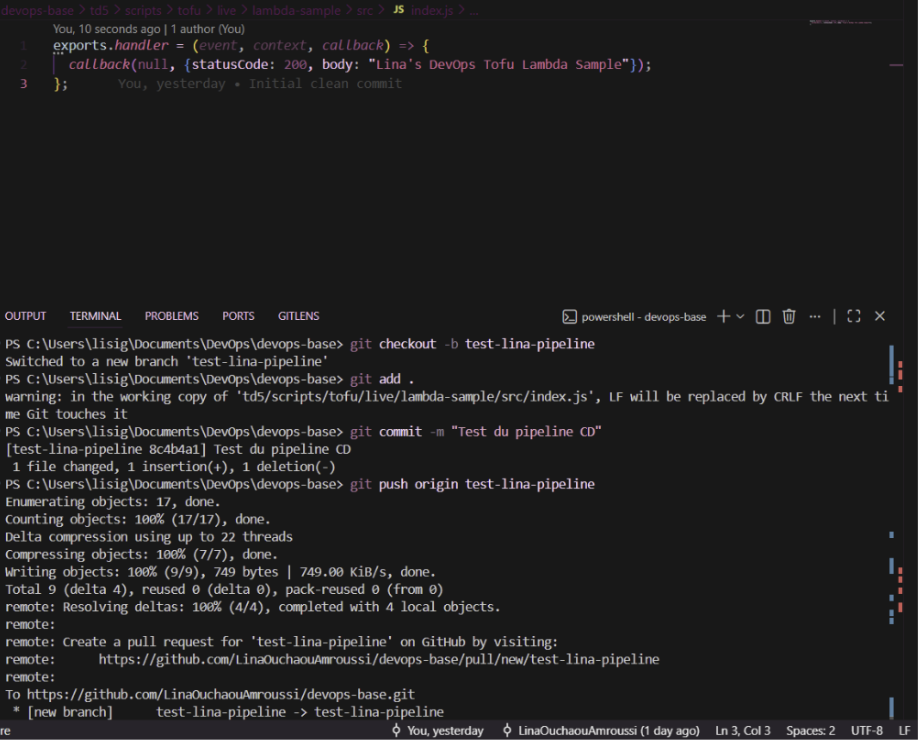 Création de la branche et interface de comparaison GitHub montrant le changement de code dans
Création de la branche et interface de comparaison GitHub montrant le changement de code dans src/index.js.
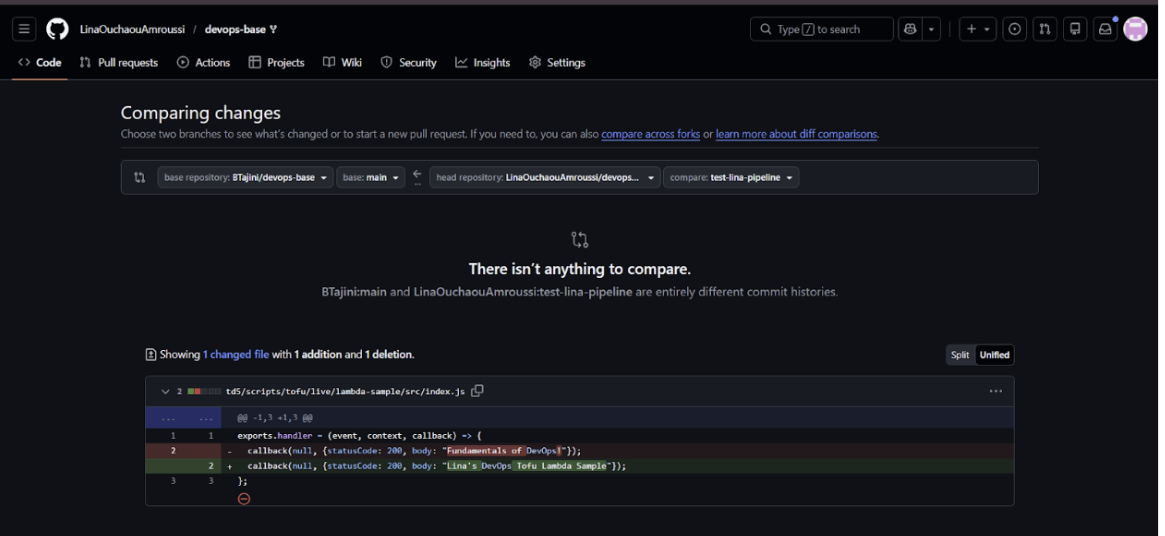 Commentaire automatisé du bot GitHub confirmant que le plan est valide, nous autorisant à procéder au “Merge” en toute sécurité.
Commentaire automatisé du bot GitHub confirmant que le plan est valide, nous autorisant à procéder au “Merge” en toute sécurité.
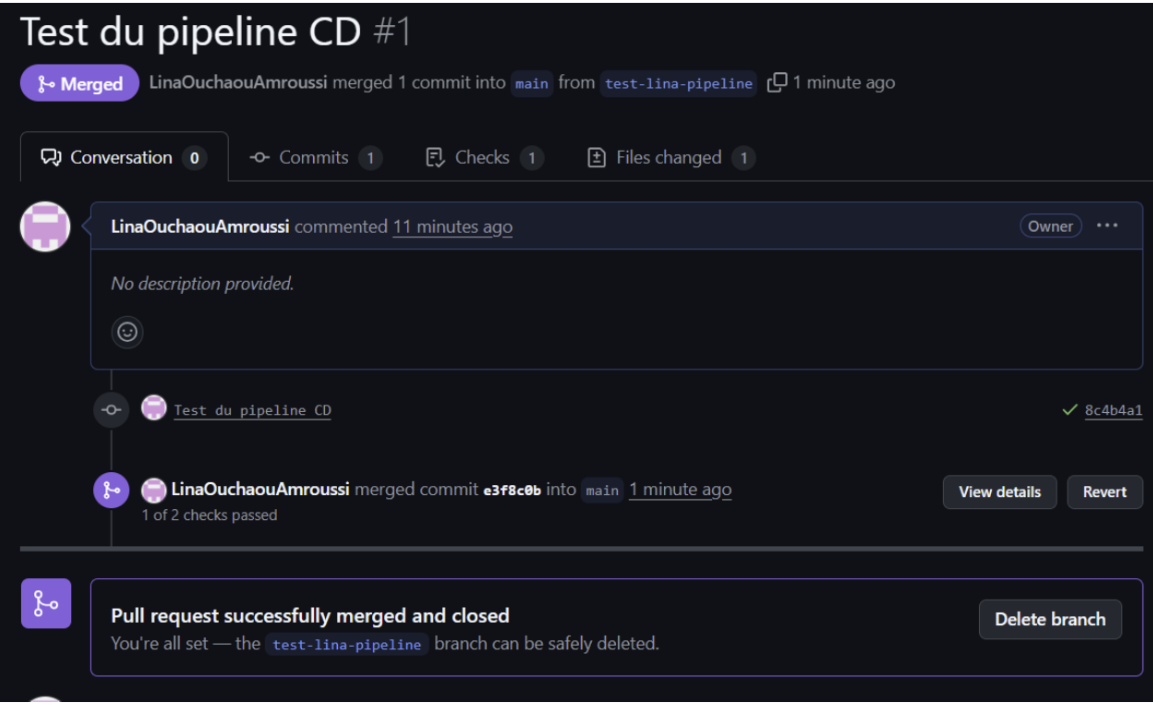 Merge validé après vérification.
Merge validé après vérification.
Déploiement Final et Vérification du Changement de Texte
Une fois la Pull Request fusionnée (merged) sur la branche main, le workflow tofu-apply.yml a pris le relais pour appliquer réellement les changements sur AWS. C’est à ce moment précis que la nouvelle version du code, contenant le message personnalisé “Lina’s DevOps Tofu Lambda Sample”, a été injectée dans la fonction Lambda. La pipeline a alors utilisé le rôle IAM d’application pour mettre à jour l’API Gateway et la Lambda de manière atomique. Pour confirmer la réussite totale de ce cycle, nous avons consulté l’URL publique générée par AWS.
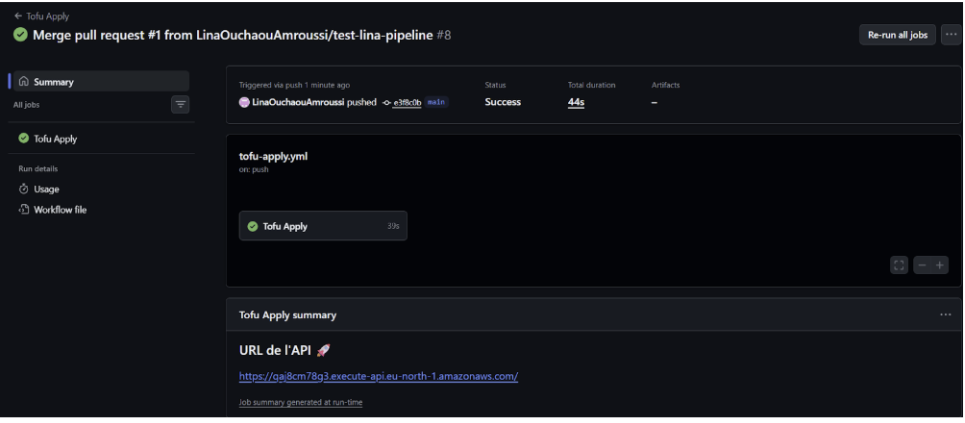 Résumé GitHub montrant le succès du workflow Tofu Apply après le merge de la PR.
Résumé GitHub montrant le succès du workflow Tofu Apply après le merge de la PR.
 La réussite du cycle CD est attestée par cette vue du navigateur. Le changement de texte est bien effectif en ligne.
La réussite du cycle CD est attestée par cette vue du navigateur. Le changement de texte est bien effectif en ligne.
Améliorations possibles du Pipeline
Même si le pipeline actuel fonctionne bien pour notre Lambda, on pourrait l’améliorer pour gérer des projets plus gros. Une idée intéressante serait de rendre la détection des changements plus intelligente. Pour l’instant, le workflow surveille seulement le dossier lambda-sample. Dans un vrai projet avec beaucoup de services, il vaudrait mieux utiliser une action comme changed-files. Cela permettrait à GitHub Actions de savoir exactement quel dossier a été modifié et de ne lancer le Plan et l’Apply que sur ce dossier, ce qui ferait gagner du temps.
On pourrait aussi utiliser une stratégie de matrice (matrix strategy). Si on modifie plusieurs dossiers d’un coup, GitHub pourrait lancer les déploiements en parallèle au lieu de les faire les uns après les autres. Enfin, pour plus de sécurité, il faudrait créer des secrets PLAN_ROLE_ARN et APPLY_ROLE_ARN différents pour chaque environnement (test, pré-production, production). Cela permettrait de bien isoler les droits et d’éviter qu’une erreur en test n’impacte la production.
Conclusion du Lab
Ce TP nous a permis de comprendre les bases du DevOps en automatisant tout le cycle de vie d’une infrastructure cloud. On est partie d’un déploiement manuel sur notre PC pour arriver à une architecture solide où l’état de l’infrastructure est stocké de façon sécurisée sur AWS S3 et DynamoDB. L’ajout des tests (unitaires et d’infrastructure avec OpenTofu) a montré qu’il est indispensable de tout vérifier automatiquement pour éviter les erreurs avant de mettre en ligne.
Le point le plus intéressant a été la mise en place de la sécurité avec OIDC et les rôles IAM. En arrêtant d’utiliser des clés d’accès classiques et en limitant les droits de chaque étape (Plan vs Apply), on a créé un pipeline de déploiement (CD) vraiment sécurisé. Ce projet montre bien qu’avec les bons outils et une bonne gestion de l’état, on peut déployer du code rapidement et de manière fiable, ce qui est l’objectif principal du DevOps aujourd’hui.