Cours : DevOps — ESIEE Paris 2025/2026
Encadrant : Badr TAJINI
Rendu : Projet Final — Pipeline CI/CD orienté données sur Kubernetes
Introduction et Présentation du Projet
Contexte et Motivations
Ce rapport présente le travail réalisé dans le cadre du projet final du cours DevOps dispensé à l’ESIEE. L’objectif pédagogique de ce projet est de mettre en œuvre l’ensemble de la chaîne DevOps allant du code source jusqu’à l’application déployée en production tout en s’appuyant sur des technologies industrielles réelles : conteneurs Docker, orchestration Kubernetes, infrastructure-as-code avec OpenTofu, et pipeline d’automatisation via GitHub Actions.
Nous avons choisi de développer Trend Tracker Pro, une application d’analyse de sentiments orientée données. Cette application permet à un utilisateur de soumettre des commentaires d’utilisateurs d’un produit commercialisé et d’en analyser la polarité émotionnelle (positive, négative ou neutre) grâce à un modèle de traitement du langage naturel (NLP) basé sur la librairie Transformers de Hugging Face, puis de visualiser l’historique des analyses sous forme de graphiques interactifs. Ce choix de thématique nous a permis d’explorer simultanément les aspects DevOps (déploiement et automatisation) et Data Science (modèle NLP et persistance des résultats).
Objectifs Techniques
Ce projet couvre quatre grandes dimensions techniques. La première concerne la conteneurisation de chaque composant applicatif via Docker, en veillant à l’optimisation des images pour réduire les temps de build et les coûts de transfert. La deuxième dimension porte sur l’intégration continue (CI), c’est-à-dire l’automatisation de la construction et des tests à chaque modification du code source. La troisième dimension traite de la livraison continue (CD), soit le déploiement automatique sur un cluster Kubernetes hébergé dans le cloud AWS. Enfin, la quatrième dimension aborde la gestion des données avec une base de données MongoDB conteneurisée et les opérations de lecture et d’écriture associées.
Architecture Globale du Projet
Choix de l’Architecture Microservices
L’application a été conçue selon le principe des microservices, c’est-à-dire en décomposant le système en composants indépendants ayant chacun une responsabilité unique. Ce choix architectural présente plusieurs avantages déterminants dans un contexte DevOps : chaque service peut être mis à jour, redéployé ou mis à l’échelle indépendamment des autres, ce qui réduit le risque d’impact en cascade lors d’une modification. Concrètement, notre architecture se compose de trois services distincts qui communiquent entre eux au sein du cluster Kubernetes.
Le Frontend est une interface utilisateur développée avec la librairie VueJS. Ce choix a été motivé par la rapidité de développement qu’elle offre pour des applications de visualisation de données : il est possible de créer des formulaires, des graphiques et des tableaux de bord interactifs. Le frontend écoute sur le port 8501 et est le seul composant exposé à l’extérieur du cluster via un LoadBalancer.
Le Backend est une API RESTful développée avec FastAPI, un framework Python moderne reconnu pour ses performances élevées (basé sur ASGI) et sa génération automatique de documentation OpenAPI. Il expose notamment un endpoint POST /analyze qui reçoit un texte, appelle le modèle NLP, et persiste le résultat dans la base de données. Il écoute sur le port 8000 et n’est accessible qu’à l’intérieur du cluster (service de type ClusterIP).
La Base de données est une instance MongoDB déployée en tant que pod Kubernetes. MongoDB, en tant que base de données NoSQL orientée documents, a été choisi pour sa flexibilité de schéma : les résultats d’analyse (texte, score, date, métadonnées) peuvent varier en structure sans nécessiter de migration de schéma, contrairement à une base de données relationnelle. Elle écoute sur le port 27017 et est également protégée par un service ClusterIP.
Schéma d’Architecture
┌─────────────────────────────────────────────────┐
│ AWS Cloud (eu-north-1) │
│ │
Internet │ ┌──────────────────────────────────────────┐ │
─────────► Classic │ VPC vpc-lina-justine-v2 │ │
Load │ │ │ │
Balancer│ │ ┌──── Subnet Public ────┐ │ │
│ │ │ │ │ │
│ │ │ Internet Gateway │ │ │
│ │ └───────────────────────┘ │ │
│ │ │ │
│ │ ┌──── Subnet Privé ─────────────────┐ │ │
│ │ │ ┌──────────────────────────────┐ │ │ │
│ │ │ │ Cluster EKS (K8s) │ │ │ │
│ │ │ │ ┌────────┐ ┌───────────┐ │ │ │ │
│ │ │ │ │Frontend│ │ Backend │ │ │ │ │
│ │ │ │ │ Pod │◄─►│ Pod │ │ │ │ │
│ │ │ │ │ :8501 │ │ :8000 │ │ │ │ │
│ │ │ │ └────────┘ └─────┬─────┘ │ │ │ │
│ │ │ │ │ │ │ │ │
│ │ │ │ ┌─────▼─────┐ │ │ │ │
│ │ │ │ │ MongoDB │ │ │ │ │
│ │ │ │ │ Pod │ │ │ │ │
│ │ │ │ │ :27017 │ │ │ │ │
│ │ │ └──────────────└───────────┘──┘ │ │ │
│ │ └─────────────────────────────────┘ │ │
│ └──────────────────────────────────────────┘ │
└─────────────────────────────────────────────────┘
Tableau des Composants Techniques
| Composant | Technologie | Port | Accessibilité | Rôle |
|---|---|---|---|---|
| Frontend | VUEJS | 8501 | Public (LoadBalancer) | Interface utilisateur, visualisation |
| Backend | FastAPI + Uvicorn | 8000 | Interne (ClusterIP) | API REST, logique NLP |
| Base de données | MongoDB 6.0 | 27017 | Interne (ClusterIP) | Persistance des analyses |
| Orchestrateur | AWS EKS (K8s 1.31) | — | Managé AWS | Gestion des pods et services |
| Réseau | VPC + NAT Gateway | — | AWS | Isolation et routage réseau |
| Registry | Docker Hub | — | Internet | Stockage des images Docker |
| IaC | OpenTofu 1.x | — | GitHub Actions | Provisionnement infra |
Structure du Projet et Organisation des Fichiers
Principes d’Organisation
Une structure de projet claire et modulaire est une condition sine qua non pour un pipeline CI/CD efficace. Dans notre cas, elle permet au pipeline GitHub Actions de détecter quels composants ont été modifiés et de n’en rebuild que les images nécessaires, réduisant ainsi le temps d’exécution et les ressources consommées. Nous avons adopté une séparation nette entre le code applicatif, la configuration d’infrastructure et les manifestes d’orchestration.
Arborescence du Dépôt
Dev-Ops/
├── projet_final/
│ │
│ ├── backend/ # Service API FastAPI
│ │ ├── main.py # Point d'entrée de l'API
│ │ ├── models.py # Modèles Pydantic (validation des données)
│ │ ├── database.py # Connexion et opérations MongoDB
│ │ ├── requirements.txt # Dépendances Python du backend
│ │ └── Dockerfile # Image Docker du backend
│ │
│ ├── frontend/ # Service Interface VueJS
│ │ ├── app.py # Application Vue.js de test du backend
│ │ ├── App.vue # Application développé du frontend
│ │ ├── package.json # Dépendances Node (build Vite)
│ │ └── Dockerfile # Image Docker multi-stage (Node + Nginx)
│ │
│ ├── k8s-manifests/ # Manifestes Kubernetes
│ │ ├── backend.yaml # Deployment + Service du backend
│ │ ├── frontend.yaml # Deployment + Service LoadBalancer du frontend
│ │ └── database.yaml # Deployment + PVC + Service de MongoDB
│ │
│ └── terraform/modules # Infrastructure as Code (OpenTofu)
│ ├── main.tf # Ressources principales (EKS, VPC)
│ ├── variables.tf # Variables paramétrables
│ ├── outputs.tf # Sorties (URL du cluster, etc.)
│ └── (providers.tf # Configuration du provider AWS)
│
└── .github/
└── workflows/
└── pipeline.yml # Pipeline CI/CD complet
Cette organisation suit la convention des projets DevOps professionnels. Chaque répertoire de premier niveau correspond à un contexte de build Docker distinct, ce qui permet à GitHub Actions d’utiliser le paramètre context: pour ne builder que le composant modifié. Les fichiers d’infrastructure OpenTofu sont regroupés dans un dossier dédié pour séparer clairement le “quoi déployer” (code applicatif) du “où déployer” (infrastructure cloud).
Phase 1 : Développement Applicatif et Conteneurisation
Le Backend FastAPI
Le backend constitue le cœur logique de l’application. Il expose une API RESTful dont les routes sont définies avec FastAPI. Le choix de FastAPI sur Flask ou Django repose sur trois arguments : ses performances natives grâce au support de l’asyncio Python, sa validation automatique des données via Pydantic, et la génération automatique d’une documentation interactive.
Point d’entrée de l’API
Le fichier main.py définit les routes de l’application. La route principale POST /analyze reçoit un texte, instancie le pipeline NLP via la librairie transformers de Hugging Face, puis persiste le résultat dans MongoDB avant de le retourner au client :
# backend/main.py
from fastapi import FastAPI
from motor.motor_asyncio import AsyncIOMotorClient
from transformers import pipeline
from datetime import datetime
from models import TextData, AnalysisResult
import os
app = FastAPI(title="Trend Tracker Pro API", version="1.0.0")
# Connexion MongoDB via le DNS interne Kubernetes
MONGO_URL = os.getenv("MONGO_URL", "mongodb://mongodb:27017")
client = AsyncIOMotorClient(MONGO_URL)
db = client.trend_tracker
# Chargement du modèle NLP au démarrage (une seule fois)
sentiment_pipeline = pipeline(
"sentiment-analysis",
model="distilbert-base-uncased-finetuned-sst-2-english"
)
@app.post("/analyze", response_model=AnalysisResult)
async def analyze_text(data: TextData):
"""
Analyse le sentiment d'un texte et le persiste en base.
Opération CRUD : Create (INSERT INTO analyses)
"""
result = sentiment_pipeline(data.text)[0]
record = {
"text": data.text,
"label": result["label"], # "POSITIVE" ou "NEGATIVE"
"score": result["score"], # Confiance du modèle (0 à 1)
"created_at": datetime.utcnow()
}
# Insertion en base de données (opération CREATE du CRUD)
inserted = await db.analyses.insert_one(record)
record["id"] = str(inserted.inserted_id)
return record
@app.get("/analyses")
async def get_analyses(limit: int = 50):
"""
Récupère l'historique des analyses.
Opération CRUD : Read (SELECT FROM analyses)
"""
cursor = db.analyses.find().sort("created_at", -1).limit(limit)
results = await cursor.to_list(length=limit)
for r in results:
r["id"] = str(r["_id"])
return results
@app.get("/health")
async def health_check():
"""Endpoint de santé pour les readinessProbes Kubernetes."""
return {"status": "healthy", "timestamp": datetime.utcnow()}La variable d’environnement MONGO_URL est un point essentiel : au lieu d’écrire l’adresse de la base de données en dur dans le code, on la lit depuis l’environnement. Dans Kubernetes, cette variable sera injectée via le manifeste YAML, ce qui nous permet de changer la configuration sans modifier le code source.
Dockerfile du Backend
Le Dockerfile du backend utilise une image de base python:3.12-slim. Le suffixe -slim est intentionnel : il correspond à une variante allégée de l’image Python officielle qui ne contient que les fichiers strictement nécessaires à l’exécution, excluant notamment les compilateurs et outils de développement. Cela réduit la taille de l’image de ~900 Mo à ~150 Mo, ce qui diminue les temps de transfert vers Docker Hub et les temps de démarrage des pods :
# backend/Dockerfile
FROM python:3.12-slim
# Création du répertoire de travail
WORKDIR /app
# Copie et installation des dépendances en premier (layer caching Docker)
# Cette optimisation évite de réinstaller les dépendances si seul le code change
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# Copie du code source après les dépendances
COPY . .
# Exposition du port d'écoute (documentation, non fonctionnel seul)
EXPOSE 8000
# Commande de démarrage avec Uvicorn (serveur ASGI)
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]L’ordre des instructions dans un Dockerfile est crucial pour l’efficacité du cache Docker. En copiant requirements.txt avant le reste du code, on exploite le système de cache en couches (layers) de Docker : si seul le code Python change mais pas les dépendances, Docker n’exécutera pas à nouveau le RUN pip install, accélérant considérablement les builds successifs.
 Figure 1 : Log de build Docker du backend dans GitHub Actions
Figure 1 : Log de build Docker du backend dans GitHub Actions
Le Frontend avec Vue.js
Pour la partie interface de notre projet, nous avons choisi d’utiliser le framework Vue.js, car il permet de créer des pages web dynamiques et réactives de manière très structurée. Ayant suivi une unité de développement web avec ce framework, nous étions particulièrement à l’aise pour l’utiliser. L’objectif était de concevoir un tableau de bord capable d’afficher en temps réel les résultats de l’analyse de sentiment. L’interface est organisée en deux colonnes : à gauche, un formulaire permet de configurer le nom du produit et de saisir le ou les commentaires à analyser, tandis qu’à droite, les résultats sont visualisés instantanément grâce à des graphiques intégrés (diagramme circulaire et barres de volume). Nous avons utilisé la bibliothèque Axios pour faire le lien avec l’API Python, ce qui permet au Front-end d’envoyer les textes et de récupérer les statistiques sans recharger la page. Par ailleurs, nous nous sommes rendu compte que lorsque nous rechargions la page, le formulaire avec les commentaires s’effaçait mais pas les résultats affichés sur les graphiques. Ainsi, nous avons eu l’idée d’ajouter un bouton pour réinitialiser la page. Concernant le design, nous avons utilisé Tailwind CSS, un outil qui facilite la mise en page et rend l’application claire et moderne, garantissant une navigation intuitive pour les utilisateurs.
Le frontend utilise une approche de build multi-stage dans son Dockerfile. Cette technique avancée consiste à utiliser deux images de base successivement dans un même Dockerfile : la première (Node.js) compile les assets statiques avec Vite, et la seconde (Nginx) sert les fichiers compilés. L’image finale ne contient que Nginx et les fichiers compilés, sans aucun outil Node.js, réduisant drastiquement sa taille :
# frontend/Dockerfile
# Étape 1 : Build avec Node.js (image temporaire, non incluse dans l'image finale)
FROM node:20-slim AS build-stage
WORKDIR /app
COPY package*.json ./
# Installation des dépendances Node
RUN npm install
COPY . .
# Compilation des assets pour la production (Vite)
RUN npm run build
# Résultat : répertoire /app/dist avec les fichiers HTML/CSS/JS minifiés
# Étape 2 : Serveur de production (seule cette étape est dans l'image finale)
FROM nginx:stable-alpine
# Copie uniquement des fichiers compilés depuis l'étape précédente
COPY --from=build-stage /app/dist /usr/share/nginx/html
EXPOSE 80
CMD ["nginx", "-g", "daemon off;"]Phase 2 : Infrastructure as Code avec OpenTofu
Pourquoi nous avons choisit OpenTofu et non Minikube ?
Le choix d’AWS EKS via OpenTofu plutôt que Minikube en local est une décision structurante qui mérite justification. Minikube simule un cluster Kubernetes sur la machine locale, ce qui est parfait pour apprendre, mais ne représente pas la réalité d’un déploiement en production ce que nous voulions vraiment mettre en place dans le cadre de ce projet : pas de gestion IAM, pas de réseau VPC. En optant pour EKS, nous avons choisi de nous confronter dès le projet de cours aux problématiques réelles du cloud : gestion des quotas, sécurité des réseaux, coûts et facturation.
OpenTofu est un fork open-source de Terraform, créé après le changement de licence de ce dernier en 2023. IL utilise la même syntaxe HCL et les mêmes providers, garantissant une compatibilité totale avec l’écosystème Terraform existant, tout en restant entièrement gratuit et communautaire.
Configuration du VPC et du Réseau
Le réseau est le fondement de toute l’infrastructure. Nous avons défini un Virtual Private Cloud (VPC) avec une plage d’adresses IP 10.0.0.0/16, divisée en quatre sous-réseaux répartis sur deux zones de disponibilité AWS (eu-north-1a et eu-north-1b) pour assurer la haute disponibilité :
# terrafom/modules/main.tf — Module VPC
module "vpc" {
source = "terraform-aws-modules/vpc/aws"
version = "~> 5.0"
name = "vpc-lina-justine-v2"
cidr = "10.0.0.0/16"
# Deux zones de disponibilité pour la haute disponibilité
azs = ["eu-north-1a", "eu-north-1b"]
# Sous-réseaux privés : hébergent les nœuds EKS (non accessibles depuis Internet)
private_subnets = ["10.0.1.0/24", "10.0.2.0/24"]
# Sous-réseaux publics : hébergent le Load Balancer (accessible depuis Internet)
public_subnets = ["10.0.101.0/24", "10.0.102.0/24"]
# NAT Gateway : permet aux pods dans les sous-réseaux privés d'accéder à Internet
# (pour télécharger les images Docker depuis Docker Hub)
enable_nat_gateway = true
single_nat_gateway = true # Une seule NAT Gateway pour économiser les coûts
# Tags requis par EKS pour identifier les sous-réseaux
public_subnet_tags = {
"kubernetes.io/role/elb" = 1 # Autoriser EKS à créer des Load Balancers ici
}
private_subnet_tags = {
"kubernetes.io/role/internal-elb" = 1
}
}Configuration du Cluster EKS
Le cluster EKS est le composant le plus structurant de l’infrastructure. La version Kubernetes choisie (1.31) est la version stable la plus récente disponible au moment du projet. Nous avons utilisé un module Terraform communautaire (terraform-aws-modules/eks) qui encapsule la complexité de la création d’un cluster EKS : rôles IAM, groupes de sécurité, addons (CoreDNS, kube-proxy, vpc-cni) :
# infrastructure/main.tf — Module EKS
module "eks" {
source = "terraform-aws-modules/eks/aws"
version = "~> 20.0"
cluster_name = "eks-lina-justine-v2"
cluster_version = "1.31"
# Réseau : déployer le cluster dans nos sous-réseaux privés
vpc_id = module.vpc.vpc_id
subnet_ids = module.vpc.private_subnets
# Endpoint public : permet au pipeline GitHub Actions de déployer les pods
cluster_endpoint_public_access = true
# Groupes de nœuds managés (Node Groups)
eks_managed_node_groups = {
nodes = {
instance_types = ["t3.small"] # Choix économique (2 vCPU, 2 Go RAM)
min_size = 1
max_size = 3
desired_size = 2 # 2 nœuds par défaut pour la résilience
}
}
# Accès IAM : autoriser le rôle GitHub Actions à déployer des pods
access_entries = {
github_actions = {
principal_arn = "arn:aws:iam::982597090285:role/projet-final-deployer-apply"
policy_associations = {
admin = {
policy_arn = "arn:aws:eks::aws:cluster-access-policy/AmazonEKSClusterAdminPolicy"
access_scope = { type = "cluster" }
}
}
}
}
}Le choix des instances t3.small est un compromis délibéré entre coût (~0.02$/h par instance) et capacité. Ces instances offrent suffisamment de ressources pour faire tourner les pods NLP tout en restant dans une enveloppe budgétaire raisonnable.
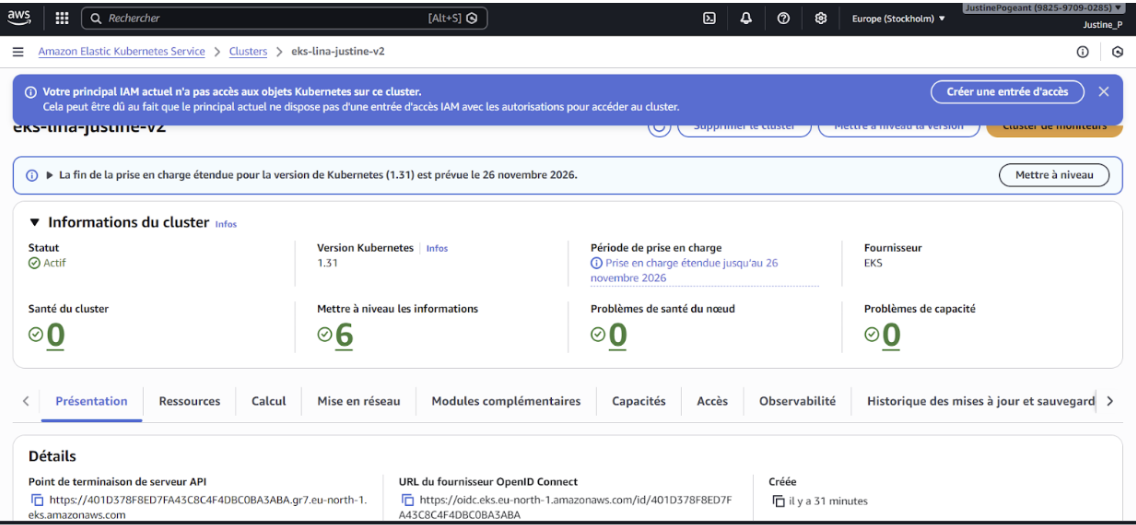 Figure 2 : Console AWS EKS montrant le cluster eks-lina-justine-v2 en statut “Actif”
Figure 2 : Console AWS EKS montrant le cluster eks-lina-justine-v2 en statut “Actif”
Phase 3 : Pipeline CI/CD avec GitHub Actions
Architecture du Pipeline
Le pipeline CI/CD est le chef d’orchestre de toute l’automatisation. Il est déclenché à chaque push sur la branche main et exécute séquentiellement les étapes de build, push et déploiement. Nous avons choisi GitHub Actions pour sa profonde intégration avec le dépôt de code, son écosystème riche d’actions communautaires et sa gratuité pour les dépôts publics.
Le pipeline est découpé en plusieurs étapes logiques :
Étape 1 — Checkout : Récupération du code source depuis le dépôt GitHub.
Étape 2 — Authentification Docker : Connexion à Docker Hub via des secrets GitHub (les identifiants ne sont jamais visibles dans les logs, ils sont masqués par ***).
Étape 3 — Build & Push : Construction des images Docker et envoi vers Docker Hub avec le SHA du commit comme tag, garantissant l’unicité et la traçabilité de chaque image.
Étape 4 — Authentification AWS : Connexion à AWS via OIDC (OpenID Connect), une méthode sans secret statique plus sécurisée que les clés AWS classiques.
Étape 5 — OpenTofu Apply : Provisionnement ou mise à jour de l’infrastructure AWS (VPC, EKS).
Étape 6 — Déploiement K8s : Application des manifestes Kubernetes sur le cluster EKS.
Extrait du Fichier de Pipeline
# .github/workflows/ci-cd.yml
name: "Final Project CI-CD"
on:
push:
branches: [main]
jobs:
ci-cd:
runs-on: ubuntu-latest
permissions:
id-token: write # Requis pour l'authentification OIDC avec AWS
contents: read
steps:
# Étape 1 : Récupération du code source
- name: Checkout code
uses: actions/checkout@v3
# Étape 2 : Authentification Docker Hub
- name: Login to Docker Hub
uses: docker/login-action@v2
with:
username: ${{ secrets.DOCKERHUB_USERNAME }}
password: ${{ secrets.DOCKERHUB_TOKEN }}
# Étape 3a : Build et Push du Backend
- name: Build and push Backend
uses: docker/build-push-action@v2
with:
context: ./projet_final/backend # Contexte de build isolé
push: true
# Tag avec le SHA du commit pour garantir l'unicité
tags: ${{ secrets.DOCKERHUB_USERNAME }}/backend:${{ github.sha }}
# Étape 3b : Build et Push du Frontend (multi-stage)
- name: Build and push Frontend
uses: docker/build-push-action@v2
with:
context: ./projet_final/frontend
push: true
tags: ${{ secrets.DOCKERHUB_USERNAME }}/frontend:${{ github.sha }}
# Étape 4 : Authentification AWS via OIDC (sans clé statique)
- name: Configure AWS Credentials
uses: aws-actions/configure-aws-credentials@v3
with:
role-to-assume: arn:aws:iam::982597090285:role/projet-final-deployer-apply
aws-region: eu-north-1
# Étape 5 : Installation et exécution d'OpenTofu
- name: Setup OpenTofu
uses: opentofu/setup-opentofu@v1
- name: Tofu Init
run: tofu init
working-directory: ./projet_final/terraform
- name: Tofu Apply
run: tofu apply -auto-approve
working-directory: ./projet_final/terraform
# Étape 6 : Déploiement sur Kubernetes
- name: Deploy to Kubernetes
run: |
# Récupération des credentials du cluster EKS
aws eks update-kubeconfig \
--name eks-lina-justine-v2 \
--region eu-north-1
# Substitution des placeholders par les vraies images taguées
sed -i "s|DOCKER_IMAGE_BACKEND|${{ secrets.DOCKERHUB_USERNAME }}/backend:${{ github.sha }}|g" \
projet_final/k8s-manifests/backend.yaml
sed -i "s|DOCKER_IMAGE_FRONTEND|${{ secrets.DOCKERHUB_USERNAME }}/frontend:${{ github.sha }}|g" \
projet_final/k8s-manifests/frontend.yaml
# Application des manifestes Kubernetes
kubectl apply -f projet_final/k8s-manifests/L’utilisation du SHA de commit (${{ github.sha }}) comme tag d’image est une bonne pratique essentielle. Elle garantit que chaque déploiement est lié à une version précise du code, facilitant les rollbacks et le débogage. Utiliser le tag latest serait contre productif pour notre projet car il ne permet pas de savoir quelle version exacte est en cours d’exécution.
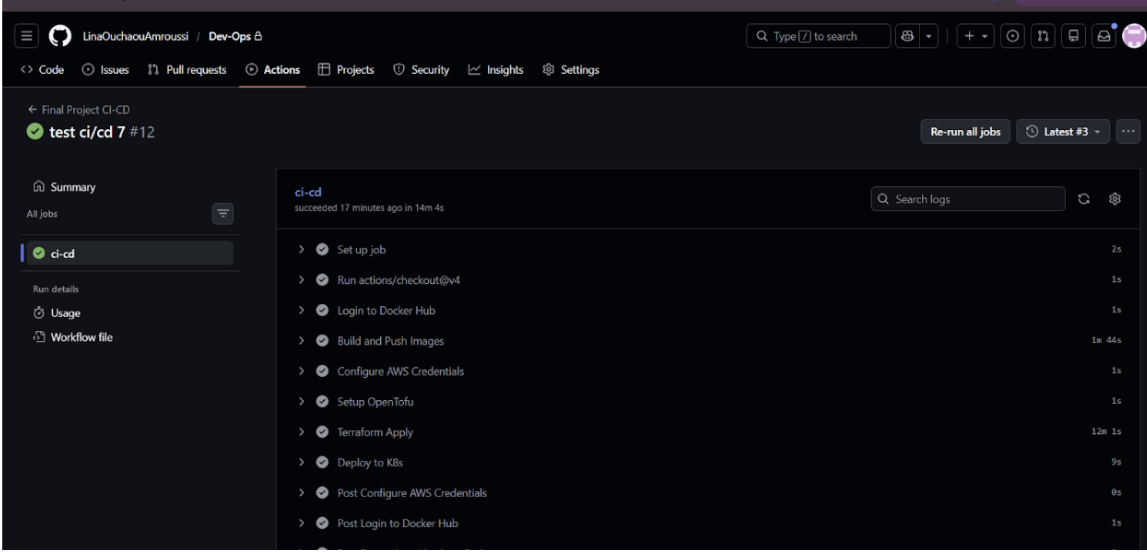 Figure 3 :Vue de l’onglet GitHub Actions montrant le Run #12 avec tous les jobs en vert (succeeded in 14m 4s)
Figure 3 :Vue de l’onglet GitHub Actions montrant le Run #12 avec tous les jobs en vert (succeeded in 14m 4s)
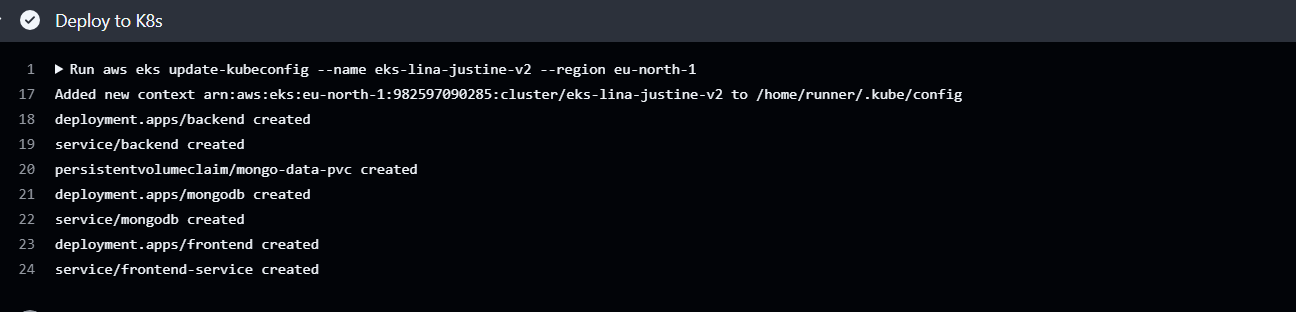 Figure 4 Détail du job “Deploy to Kubernetes” avec les lignes :
Figure 4 Détail du job “Deploy to Kubernetes” avec les lignes :
deployment.apps/backend created
deployment.apps/frontend created
service/frontend-service created
Phase 4 : Manifestes Kubernetes et Orchestration
Notre Philosophie de Configuration Kubernetes
Les manifestes Kubernetes définissent l’état désiré du système : quels conteneurs faire tourner, combien de replicas, comment les exposer en réseau, où stocker les données persistantes. Kubernetes se charge ensuite de maintenir cet état en permanence, en redémarrant les pods crashés, en redistribuant la charge et en gérant les mises à jour progressives.
Déploiement du Backend
# k8s-manifests/backend.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: backend
labels:
app: backend
spec:
replicas: 1
selector:
matchLabels:
app: backend
template:
metadata:
labels:
app: backend
spec:
containers:
- name: backend
image: DOCKER_IMAGE_BACKEND # Remplacé par sed dans le pipeline
ports:
- containerPort: 8000
env:
# Injection de la connexion MongoDB via DNS interne Kubernetes
# "mongodb" correspond au nom du Service K8s, pas une IP fixe
- name: MONGO_URL
value: "mongodb://mongodb:27017"
# Sonde de disponibilité : K8s ne routera pas de trafic avant que
# le pod réponde sur /health
readinessProbe:
httpGet:
path: /health
port: 8000
initialDelaySeconds: 30
periodSeconds: 10
---
# Service interne : accessible uniquement depuis le cluster
apiVersion: v1
kind: Service
metadata:
name: backend
spec:
selector:
app: backend
ports:
- port: 8000
targetPort: 8000
type: ClusterIP # Pas d'exposition externe = sécurité par défautDéploiement du Frontend avec LoadBalancer
# k8s-manifests/frontend.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: frontend
labels:
app: frontend
spec:
replicas: 1
selector:
matchLabels:
app: frontend
template:
metadata:
labels:
app: frontend
spec:
containers:
- name: frontend
image: DOCKER_IMAGE_FRONTEND # Remplacé par sed dans le pipeline
ports:
- containerPort: 8501
---
# Service LoadBalancer : AWS provisionne automatiquement un Classic Load Balancer
apiVersion: v1
kind: Service
metadata:
name: frontend-service
spec:
selector:
app: frontend
ports:
- port: 80
targetPort: 8501
type: LoadBalancer # Déclenche la création d'un ELB sur AWSLorsque Kubernetes voit un Service de type LoadBalancer sur AWS EKS, il appelle automatiquement l’API AWS pour créer un Classic Load Balancer, lui associer des Security Groups, et l’attacher aux nœuds du cluster. Cette intégration transparente entre Kubernetes et AWS est l’un des grands atouts d’EKS par rapport à une installation Kubernetes manuelle.
Déploiement de MongoDB avec Stockage Persistant
La gestion de la base de données est plus délicate que celle des services applicatifs car elle nécessite de la persistance : si le pod MongoDB redémarre, les données ne doivent pas être perdues. Kubernetes offre le concept de PersistentVolumeClaim (PVC) pour répondre à ce besoin :
# k8s-manifests/database.yaml
# Demande de stockage persistant (PVC)
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mongo-data-pvc
spec:
accessModes:
- ReadWriteOnce # Un seul pod peut écrire à la fois (adapté à MongoDB)
resources:
requests:
storage: 5Gi # 5 gigaoctets de stockage
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: mongodb
spec:
replicas: 1 # Une seule instance MongoDB (pas de clustering)
selector:
matchLabels:
app: mongodb
template:
metadata:
labels:
app: mongodb
spec:
containers:
- name: mongodb
image: mongo:6.0
ports:
- containerPort: 27017
volumeMounts:
# Montage du volume persistant dans le conteneur
- name: mongo-storage
mountPath: /data/db # Répertoire de données MongoDB
volumes:
- name: mongo-storage
persistentVolumeClaim:
claimName: mongo-data-pvc
---
# Service interne MongoDB
apiVersion: v1
kind: Service
metadata:
name: mongodb
spec:
selector:
app: mongodb
ports:
- port: 27017
targetPort: 27017
type: ClusterIPPhase 4 : Validation, Résultats et Application Déployée
Résultat du Déploiement
Après plusieurs itérations de débogage (voir section Post-Mortem), le Run #12 de GitHub Actions s’est terminé avec succès en 14 minutes et 4 secondes. L’ensemble des ressources Kubernetes ont été créées sans erreur :
deployment.apps/backend created
service/backend created
persistentvolumeclaim/mongo-data-pvc created
deployment.apps/mongodb created
service/mongodb created
deployment.apps/frontend created
service/frontend-service created
Accès à l’Application
Une fois le déploiement terminé, AWS a provisionné un Classic Load Balancer dont l’URL DNS publique est :
http://aa0987115629141b38fc2309530dc0a2-900570254.eu-north-1.elb.amazonaws.com:8501
L’interface Vue.js de Trend Tracker Pro était accessible depuis cette URL, validant que la chaîne complète (GitHub → Docker Hub → OpenTofu → EKS → Load Balancer → navigateur) fonctionnait correctement.
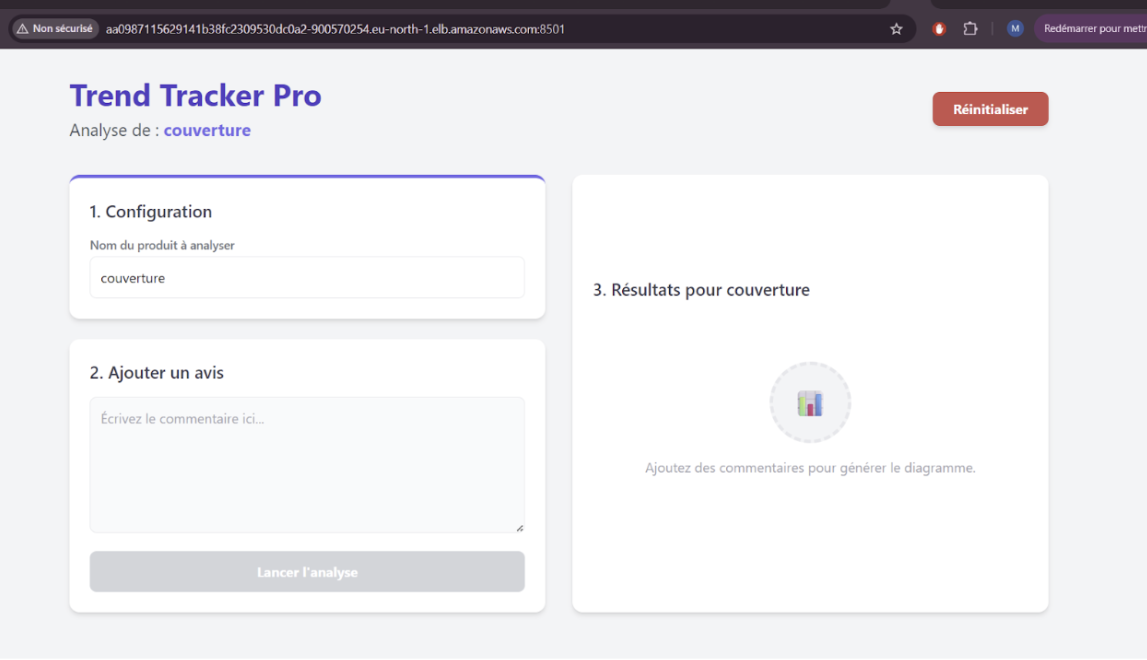 Figure 5 : Page d’accueil de Trend Tracker Pro affichée dans le navigateur, avec l’URL du Load Balancer visible dans la barre d’adresse
Figure 5 : Page d’accueil de Trend Tracker Pro affichée dans le navigateur, avec l’URL du Load Balancer visible dans la barre d’adresse
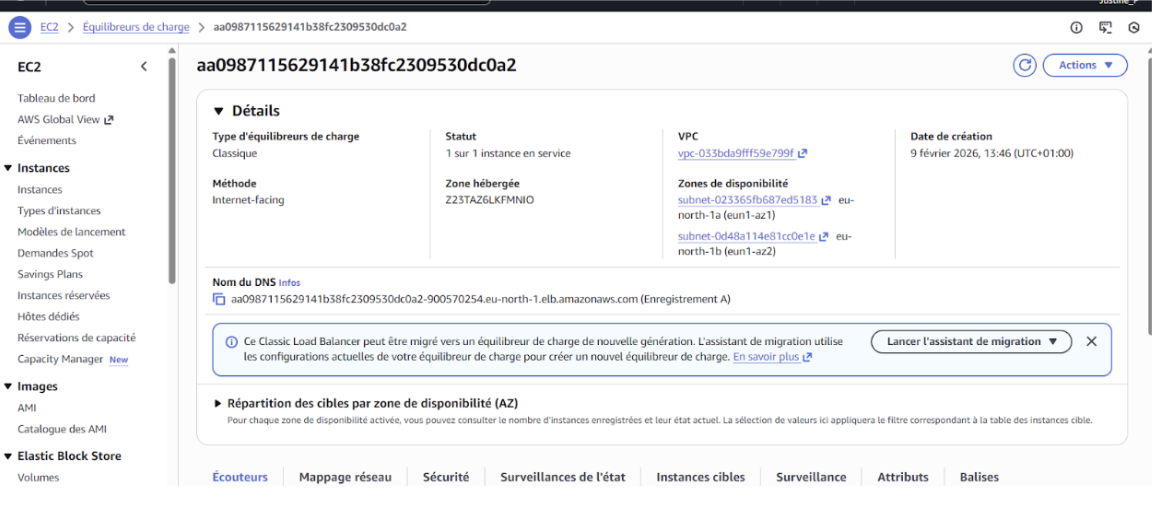 Figure 6: Console AWS EC2 → Load Balancers, montrant le Load Balancer “aa0987115629141b38fc2309530dc0a2” avec le statut “1 sur 1 instance en service”
Figure 6: Console AWS EC2 → Load Balancers, montrant le Load Balancer “aa0987115629141b38fc2309530dc0a2” avec le statut “1 sur 1 instance en service”
Gestion des Opérations CRUD
Les opérations de base de données (Create, Read, Update, Delete) ont été implémentées dans le backend FastAPI. La route POST /analyze crée un enregistrement en base après chaque analyse. La route GET /analyses permet de lire et d’afficher l’historique dans l’interface Vue.js. Ces opérations illustrent le cycle complet de manipulation de données dans une architecture microservices :
# Exemple d'opération READ pour alimenter les graphiques du frontend
@app.get("/analyses")
async def get_analyses_for_chart():
"""
Récupère les analyses regroupées par sentiment pour générer
le diagramme circulaire affiché sur l'interface.
"""
pipeline = [
{"$group": {
"_id": "$label",
"count": {"$sum": 1},
"avg_score": {"$avg": "$score"}
}},
{"$sort": {"count": -1}}
]
results = await db.analyses.aggregate(pipeline).to_list(length=10)
return resultsAnalyse des Incidents et Retour d’Expérience (Post-Mortem)
Incident 1 : Dépassement du Quota de VPC
L’un des défis les plus instructifs du projet a été la gestion des quotas AWS. Par défaut, AWS limite chaque région à 5 VPCs. Suite à plusieurs runs de pipeline qui ont partiellement créé des ressources avant d’échouer, nous nous sommes retrouvées avec 5 VPCs résiduels (“zombie resources”) dans la région eu-north-1, bloquant tout nouveau déploiement avec l’erreur VpcLimitExceeded.
La résolution a nécessité de comprendre les dépendances entre les ressources AWS et de les supprimer dans l’ordre inverse de leur création : d’abord les Node Groups EKS (pour libérer les instances EC2), puis les clusters EKS, puis les NAT Gateways (pour libérer les interfaces réseau), et enfin les VPCs. Cette expérience illustre l’importance cruciale de la gestion du cycle de vie des ressources cloud et de l’utilisation systématique de tofu destroy après chaque déploiement de test.
Incident 2 : Conflit de Noms de Ressources (State Terraform)
Lors du passage du nom eks-lina-justine à eks-lina-justine-v2, un conflit est apparu : les ressources portant le nouveau nom (alias KMS, groupe de logs CloudWatch) avaient été partiellement créées lors d’un run précédent mais n’avaient pas été enregistrées dans le fichier d’état d’OpenTofu. AWS renvoyait alors l’erreur AlreadyExistsException alors qu’OpenTofu pensait que ces ressources n’existaient pas.
Ce type de désynchronisation entre l’état réel d’AWS et l’état enregistré par OpenTofu (le fichier .tfstate) est un problème classique en pratique DevOps. La solution adoptée a été de supprimer manuellement les ressources en conflit via la console AWS pour “remettre les compteurs à zéro”, puis de relancer le pipeline.
Incident 3 : Problème d’Accès IAM/RBAC
Une erreur Error from server (Forbidden) est survenue lors de l’exécution de kubectl apply depuis GitHub Actions. L’analyse des logs a révélé que le cluster EKS avait été créé par un rôle IAM spécifique (projet-final-deployer-apply), et que Kubernetes refusait par défaut d’accorder des droits à ce même rôle lors du déploiement suivant, faute d’une entrée d’accès explicite.
La correction a consisté à ajouter un bloc access_entries dans la configuration OpenTofu du module EKS, accordant explicitement au rôle GitHub Actions les permissions d’administrateur du cluster. Cet incident a mis en lumière la différence entre l’authentification AWS (qui confirme l’identité) et l’autorisation Kubernetes RBAC (qui définit ce que l’identité peut faire dans le cluster).
Incident 4 : Suspension du Compte AWS
En fin de projet, le compte AWS a été suspendu suite au dépassement des crédits de l’offre gratuite. Une investigation a révélé qu’un cluster EKS de test (eks-lina-justine) avait été oublié dans la région us-east-1 (Virginie du Nord, utilisée lors des premiers tests), différente de la région principale eu-north-1 (Stockholm). Un cluster EKS vide génère une facturation de ~73 sur plusieurs jours.
Cet incident a conduit à l’adoption de pratiques FinOps rigoureuses : vérification systématique de toutes les régions après chaque session de travail, mise en place d’alertes de budget dans AWS Billing, et documentation de la procédure de nettoyage des ressources. Le support AWS a été contacté pour expliquer la situation étudiante et demander un geste commercial.
Leçons Apprises
| Incident | Cause Racine | Solution Appliquée | Leçon DevOps |
|---|---|---|---|
| VpcLimitExceeded | Resources zombies de runs échoués | Nettoyage manuel dans l’ordre des dépendances | Toujours vérifier les quotas avant de déployer |
| AlreadyExistsException | Désynchronisation state/réalité | Suppression manuelle + re-run | Surveiller le fichier .tfstate |
| RBAC Forbidden | Pas d’access_entries dans la config EKS | Ajout du bloc access_entries | IAM ≠ RBAC Kubernetes |
| Suspension de compte | Cluster oublié en us-east-1 | Suppression + contact support | FinOps : surveiller TOUTES les régions |
Conclusion
Ce projet nous a permis de parcourir l’intégralité du cycle de vie d’une application cloud-native, depuis l’écriture du code jusqu’à son exposition publique via un Load Balancer sur AWS. Au-delà des aspects techniques, les incidents rencontrés ont constitué la partie la plus formatrice du projet : gérer des quotas AWS dépassés, comprendre les dépendances entre ressources cloud, déboguer des problèmes RBAC Kubernetes et appliquer des pratiques FinOps pour maîtriser les coûts.
L’infrastructure déployée (VPC multi-zones, cluster EKS managé, pipeline CI/CD automatisé) constitue une base solide et reproductible grâce à l’usage d’OpenTofu. La totalité du code d’infrastructure, des manifestes Kubernetes et de la configuration du pipeline est versionnée dans le dépôt Git, ce qui permet à n’importe quel membre de l’équipe de recréer l’environnement complet depuis zéro en lançant simplement le pipeline GitHub Actions.
Annexe A — Livrables du Projet
| Livrable | Localisation | Description |
|---|---|---|
| Code Backend | projet_final/backend/ | API FastAPI + modèle NLP |
| Code Frontend | projet_final/frontend/ | Interface Vue.js |
| Manifestes K8s | projet_final/k8s-manifests/ | Deployments, Services, PVC |
| Infrastructure IaC | projet_final/terraform/ | OpenTofu (VPC + EKS) |
| Pipeline CI/CD | .github/workflows/ci-cd.yml | GitHub Actions complet |
Annexe B — Commandes de Référence
# Déploiement local (test)
kubectl apply -f projet_final/k8s-manifests/
# Vérification de l'état des pods
kubectl get pods -n default
# Récupération de l'URL du LoadBalancer
kubectl get svc frontend-service \
-o jsonpath='{.status.loadBalancer.ingress[0].hostname}'
# Destruction complète de l'infrastructure (IMPORTANT pour stopper la facturation)
cd projet_final/terraform && tofu destroy -auto-approve
# Connexion au cluster depuis une machine locale
aws eks update-kubeconfig \
--name eks-lina-justine-v2 \
--region eu-north-1Rapport rédigé dans le cadre du cours DevOps — ESIEE Paris 2025/2026